Jupyter
Having worked a bit with project jupyter, I found the documentation lacking a bit in terms of helping figure out the internals of multiple projects such as JupyterHub, JupyterLab, JupyterNotebooks etc.. Thus this is my attempt to collate my notes on all these projects and serve as a brain dump for myself whenever i need to go back to them.
Project Jupyter
It’s a community run project on github with a goal to develop open-source software, open-standards adn services for interactive computing across multiple programming languages. We are familiar with Jupyter Notebooks which are easy to use web applications for sharing and creating computational documents. It’s primarily popular in data science and realted communities as a primary IDE of choice.
Jupyter Lab
This is a project under the bigger umbrella of Project Jupyter. This serves as the new web-based interactive development environment for notebooks, code and data. JupyterLab is built to be modular and based on extensions. As of this writing JupyterLab is the default UI which comes pre-installed with JupyterHub or plain Jupyter Notebooks. It can handle mulitple formats such as Latex, Images, Rich text, Markown, Python etc.. to be run interactively. Also, JupyterLab supports writing different kernels and extensions which can compute with different environments and enhance the functionality of jupyter lab respectively.
Extensions
Any extension is a package that contains a number of JupyterLab Plugins packaged as a JupyterLab Extension.Primarily the extensions have two parts to it : server side extensions and labextensions. More about writing your own custom extension can be found here.. Every extension is made of two parts : an NPM package and a Jupyter server extension (python package).more about that here.
Jupyter Hub
This is by far the meat of the solution when considering to orchestrate an environment which can serve multiple JupyterNotebooks and manage them all for multiple users. Jupyterhub can be run in cloud or on your own hardware and makes it possible to serve pre-configured data science environment to any user in the world. To deploy in cloud there are two distributions :
The documentation for JupyterHub can be found on the docs-site and the code here.
JupyterHub like any true orchestration engine has many moving parts.
- The Hub
- Authentication
- Jupyter Config
- Spawners
- Database
- Configurable HTTP Proxy
- Single User Notebook Servers
JupyterHub is a tornado process that is heart of JupyterHub.
Tornado is a python based web framework and async networking library.
Check which version of Tornado library is used within JupyterHub version of your choice as the switch from coroutines/yield to async await isn’t done systematically and may cause issues, mainly within custom handlers which need to have async await but is not supported by jupyter hub in the chosen version.
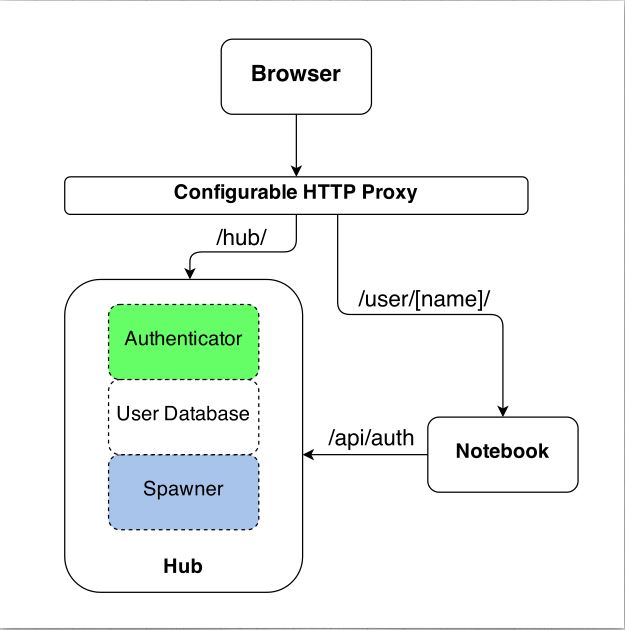
The details about how JupyterHub works is mentioned here.
To customize JupyterHub there are different authenticators and spawners to choose from, also one can write their own authenticators and spawners and add to the jupyter config file to be used at the startup.
Also, there are multiple ways to do the same thing in these thus will have to probablry go through the source code or different stack overflow/discource posts to figure out what yoy want to do with custom authenticators and spawners.
One thing to note is, passing variables from authenticator to spawners is quite common and this can be done using auth_state.
This is a special JSON serializable dictionary which should be set in the authenticate method within the Custom Authenticator this can be directly read within Custom Spawner using auth_state_hookreference_here which is implemented within most of the spawners.
Also there is a seperate way to pass strings from authenticators to spawner using environment variable within the pre_spawn_hook within Authenticator this is listed as promoted method to pass auth_state although you can only pass strings or byte like characters to it as they are stored as environment variables.
Also, JupyterHub stores session related details in a local sqlite database, these are used for operating the Hub. This can be replaced by a RDBMS as per instructions here.
This database can be changed to any other supported database such as postgres if needed. It is recommmended to change the database in production to some other managed solution as the sqlite solution can be non-deterministic/untrustworthy and has issues in cases when there isn’t enough storageg space for it work properly.
Jupyter Configurable Http Proxy
This is an nodeJs based proxy which also shows as chp pod when deployed within Kubernetes. It’s managed by Hub and it’s main focus is to first redirect all requests to hub for authentication and then once a user’s notebook server is up, redirect the requests onto it. This can be replaced by custom implementations as well (ningx, envoy etc..) which are more scalable and better suited for use with Kubernetes. References here.
JupyterHub-SingleUser
This is an individual notebook server which gets spawned from JupyterHub for any user. This environment can be customized to any individual needs by installing packages, configuring IPython or JupyterLab, adding conda environments as kernels. detailed instructions here.
Jupyter connects to individual kernels using long lived websocket connections, for which tornado framework is suitable.
Any open notebook will open a websocket connection from browser to single user notebook, this is listed within the logs for single user notebook and any activity is listed there in.
